

A Question-Answering model that answers EVERYTHING

QA model
QA model
QA model
By Sofía Sánchez González
Although NLP technology has come a long way, up until now question-answering models have been limited to the text with which we train them. If text is not provided, it would be like having a roadmap without street signs or landmarks. There would be no context. But now everything has changed with a new open domain question-answering model that answers everything.
Let’s start from the beginning.
What is question answering?
Question-answering (QA) models are information retrieval systems that search for answers to queries posed by humans and automatically communicate results in natural language. This is achieved by training them with documents such as Wikipedia pages or, in the case of a business, internal reports and forms.
Here is an example that explains a situation we might encounter at Narrativa. Imagine a report on your company’s financial results over the last 15 years. It is more than 50 pages long and contains context and details about company movements such as mergers or sales. For simplicity, you want to know the year a specific merger occurred.

Question-answering models are information retrieval systems that search for answers.
How do you get the information you need quickly? With our QA model. We pass the report to the model and ask the question: “In what year did the merger with company X take place?” The model gives the answer almost instantly, saving you the time of manually searching through pages for keywords.
Question answering systems are particularly useful in industries that manage large volumes of documentation, such as finance, legal services, and life sciences. Pharmaceutical companies and clinical research organizations often work with thousands of pages of reports, clinical trial documentation, and regulatory submissions. AI powered QA systems help teams quickly retrieve specific information from these documents.
Short summary so far: reader models
So far, reader models have been widely developed. If a question is asked and the answer exists within the context, the model identifies where the answer begins and ends. These are extractive models. If the answer does not exist in the provided text, the model produces no result.
Unity is strength: two QA models for the price of one
In the example above about the financial report, the model returned the answer we needed. But what if we need to search more than a single report? What if the question refers to information across many documents? In that case, we can use a hybrid combination of two models to achieve the best result.
Open domain QA: retriever plus reader models
Despite the name, this retriever is not related to dogs. In this context, a retriever model locates relevant information even if the question is not phrased exactly like the original text. The reader model identifies the most likely answer within that content. Together, both models work to deliver accurate responses.
You can learn more about retriever models in this article.
Big companies already use them
At Google we can already see examples of these models because the search process is greatly simplified.
Previously, Google searched manually across indexed content. Now it can identify answers more directly. For example, if we search “How to take a screenshot in Windows,” Google immediately highlights the relevant information.
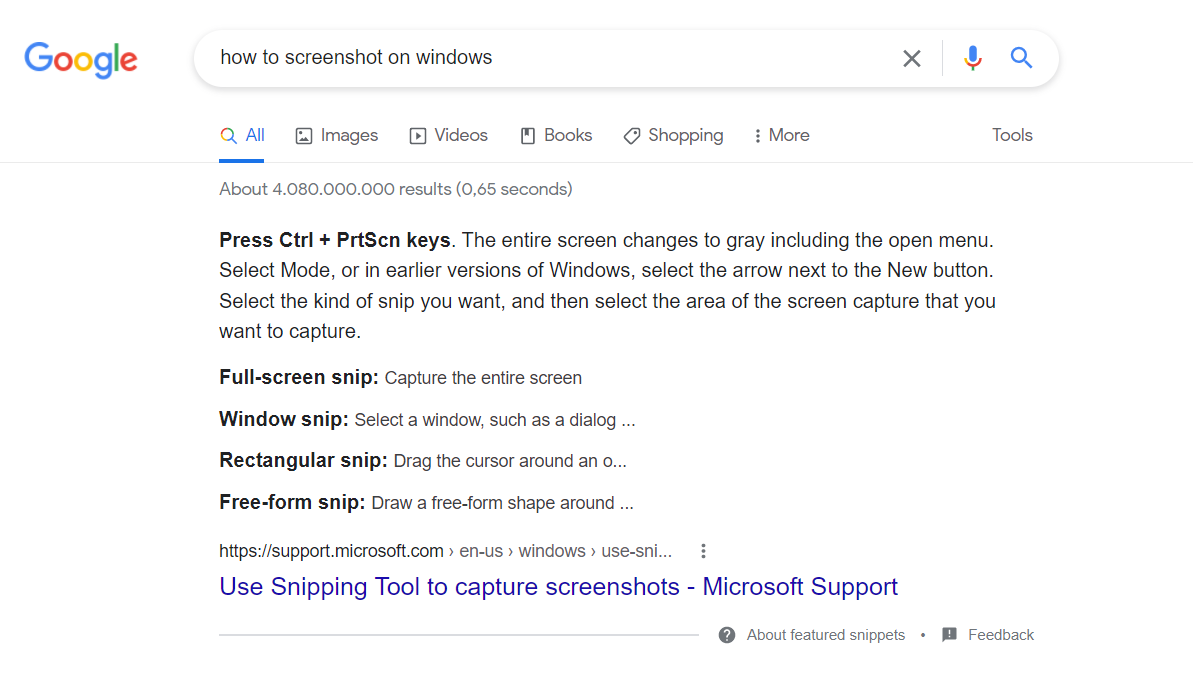
For companies that manage large volumes of documents or reports, this technology can be extremely valuable. For example, a sports media outlet might ask:
Who was Real Madrid’s top scorer last season?
There may be many articles discussing this topic, but by combining retriever and reader models, the system can provide an immediate answer.
Question answering in life sciences
Question answering models are useful for searching large document collections. However, highly regulated industries such as life sciences often require specialized AI systems.
Regulatory documentation such as clinical study reports (CSRs), patient safety narratives, and Tables, Listings, and Figures (TLFs) are generated from complex datasets that may include millions of patient data points. These documents require structured analysis and strict compliance with regulatory standards.
Because of this complexity, general open domain QA models are not always sufficient for regulatory workflows.
What about regulatory submissions?
These models are not optimized to answer regulatory submission questions related to clinical study reports (CSRs) or other regulatory documents. This is because they are not specifically designed for the requirements of the life sciences industry.
For example, they cannot automatically generate or analyze patient safety narratives or Tables, Listings, and Figures (TLFs), which contain complex information derived from millions of patient data points.
Is there an alternative for regulatory submissions? Yes. Narrativa has worked with industry leaders and medical writers to develop solutions designed specifically for life sciences workflows.
Our solutions automate processes such as patient safety narratives and TLFs. This helps accelerate the creation of clinical study reports while allowing medical writers to focus on tasks that require expert judgment.
As artificial intelligence continues to evolve, question answering systems are becoming powerful tools for navigating large document collections. When combined with specialized AI platforms designed for regulated industries, these technologies can significantly improve how organizations retrieve information, analyze data, and generate complex documentation.
About Narrativa
Narrativa® Agentic AI solutions unlock a faster, smarter future for life sciences organizations, helping them to efficiently produce complex, high-volume documentation for regulatory and commercialization workflows. By automating content creation, Narrativa® delivers greater speed, accuracy, and consistency—while ensuring full compliance in highly regulated environments.
The Narrativa® Navigator platform provides secure and specialized Agentic AI-powered automation features. It includes complementary user-friendly tools such as Clinical Atlas for CSR and Protocol generation, Narrative Pathway, TLF Voyager, and Redaction Scout, which operate cohesively to transform clinical data into submission-ready documents for regulatory and commercialization. From database to delivery, pharmaceutical sponsors, biotech firms, and contract research organizations (CROs) rely on Narrativa® to streamline workflows, decrease costs, and reduce time-to-market across the clinical lifecycle and, more broadly, throughout their entire businesses.
Explore www.narrativa.com and follow on LinkedIn, Facebook, Instagram, and X.
