

Whisper’s OpenAI: the AI whisperer model

Whisper AI
Whisper AI
Whisper AI
By Sofía Sánchez González
The world of artificial intelligence has gone crazy lately. Every week we have a new model available, but the best comes when it is an open source model. This is the case with Whisper, from OpenAI, which has overshadowed Stable Diffusion these past weeks. Whisper’s OpenAI: The AI whisperer model.
How does Whisper work?
Whisper is an Automatic Speech Recognition (ASR) system. This means that we introduce an audio track to the model and, since it is a multitasking model, you will be able to generate two things with it:
- Audio transcription
- Audio translation (from other languages to English)

Image taken from openai.com/blog/whisper/
The real life uses of Whisper are fantastic, especially if you are a content creator. If you are a YouTuber and you wish to put subtitles on your videos, Whisper can do it for you with slightly better quality, according to some users, than what YouTube itself offers. On the other hand, if you want to transcribe a podcast, just upload the audio and Whisper will quickly transform it into text.
But remember, Whisper’s main language is English.
Whisper’s strengths
Whisper is a vast improvement over the ASR systems we have seen to date. These are some of its advantages:
- It is the most robust and accurate automatic speech recognition system available.
- Whisper is very permissive when it comes to accents. You do not have to speak British English for Whisper to understand what you are saying, an important point for non native speakers. Other approaches often rely on smaller datasets where audio and text are not always paired, which reduces accent diversity.
- OpenAI’s model is capable of limiting background noise. Many existing models are unable to distinguish between silence and voice and may transcribe silence as speech.
- It is configured to understand, transcribe, and translate technical language. Whisper understands industry or niche expressions that can be difficult for other speech recognition systems.
- It makes approximately 50% fewer errors than other models.
OpenAI has surpassed other models thanks to a huge and exclusive dataset used during training.
We will give you more details.
How has Whisper been trained?
Many people wonder why OpenAI has reached places where other researchers have not been able to approach. Open research can go only so far. The data used to train the models is the most important element. It is the fuel that powers artificial intelligence.
Not all organizations have the same amount of data to train their models. In the case of Whisper, 680,000 hours of training data were used, exposing the system to large amounts of web audio content.
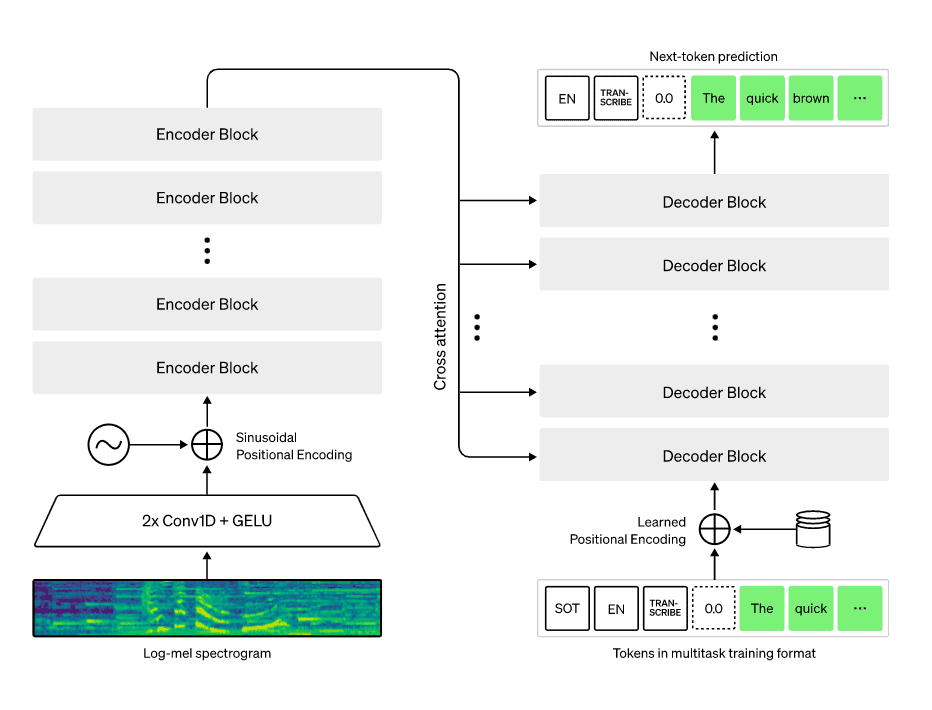
Image taken from openai.com/blog/whisper/
All of those hours were broken down into 30 second audio tracks, which is the segment length Whisper processes. If you want to transcribe a 50 minute podcast, the model converts the audio into a Mel spectrogram and splits it into 30 second segments.
The system then feeds these segments into the decoder, which performs the language identification tasks mentioned earlier: transcription and translation. Whisper has not been fine tuned on a specific dataset to avoid introducing bias.
Where can I try it?
The launch of Whisper has been open to everyone. There is no waiting list or exclusive access required. You can try it right away.
You can upload audio to Whisper:
- From a microphone
- In MP3 or MP4 format
Here you can try it. And remember, our platform seamlessly integrates this model, making it easy for you to use.

Speech recognition in life sciences
In addition to content creation, speech recognition technologies like Whisper can also support life sciences and healthcare workflows. Clinical research teams often need to transcribe interviews, investigator meetings, patient recordings, or conference presentations.
AI powered transcription tools can convert these audio recordings into structured text, making it easier to review discussions, document findings, and support clinical documentation and medical research workflows.
As AI in life sciences continues to grow, tools like Whisper can help researchers process spoken information faster and transform it into data that can be analyzed or included in reports.
About Narrativa
Narrativa® Agentic AI solutions unlock a faster, smarter future for life sciences organizations, helping them to efficiently produce complex, high-volume documentation for regulatory and commercialization workflows. By automating content creation, Narrativa® delivers greater speed, accuracy, and consistency—while ensuring full compliance in highly regulated environments.
The Narrativa® Navigator platform provides secure and specialized Agentic AI-powered automation features. It includes complementary user-friendly tools such as Clinical Atlas for CSR and Protocol generation, Narrative Pathway, TLF Voyager, and Redaction Scout, which operate cohesively to transform clinical data into submission-ready documents for regulatory and commercialization. From database to delivery, pharmaceutical sponsors, biotech firms, and contract research organizations (CROs) rely on Narrativa® to streamline workflows, decrease costs, and reduce time-to-market across the clinical lifecycle and, more broadly, throughout their entire businesses.
Explore www.narrativa.com and follow on LinkedIn, Facebook, Instagram, and X.


