

From table to text with Narrativa’s agentic AI platform

Table to Text
Table to Text
Table to Text
By Sofía Sánchez González
Agentic AI is transforming how we handle data, and at Narrativa, we’ve taken a significant step forward in automating the conversion of structured data into readable text. Our platform enables seamless extraction and summarization of information from tables, making complex data more accessible and actionable.
Advances in agentic AI
The field of agentic AI has evolved rapidly. Our platform integrates the latest advancements, offering compatibility with state-of-the-art language models, including:
- DeepSeek R1: An open-source model that delivers strong reasoning capabilities while being cost-effective. It can be deployed in private cloud environments, ensuring data security and compliance with industry regulations. Our system leverages self-guided reasoning models that prioritize precision over speed, making them ideal for regulatory and compliance-driven sectors like pharmaceuticals.
- Private instances of GPT-4o and Claude: These models offer high accuracy and adaptability for organizations requiring proprietary AI solutions.
Flexible integration with Modern Language Models
One of Narrativa’s key advantages is our ability to connect with any large language model, whether public (e.g., OpenAI models) or private. This flexibility allows us to deploy tailored AI solutions that fit different business needs, including:
- On-premise deployment for data-sensitive industries
- Small-scale implementations with lower costs while maintaining high accuracy
- Integration with modern generative models for enhanced reasoning and summarization
How does our platform’s table-to-text technology work?
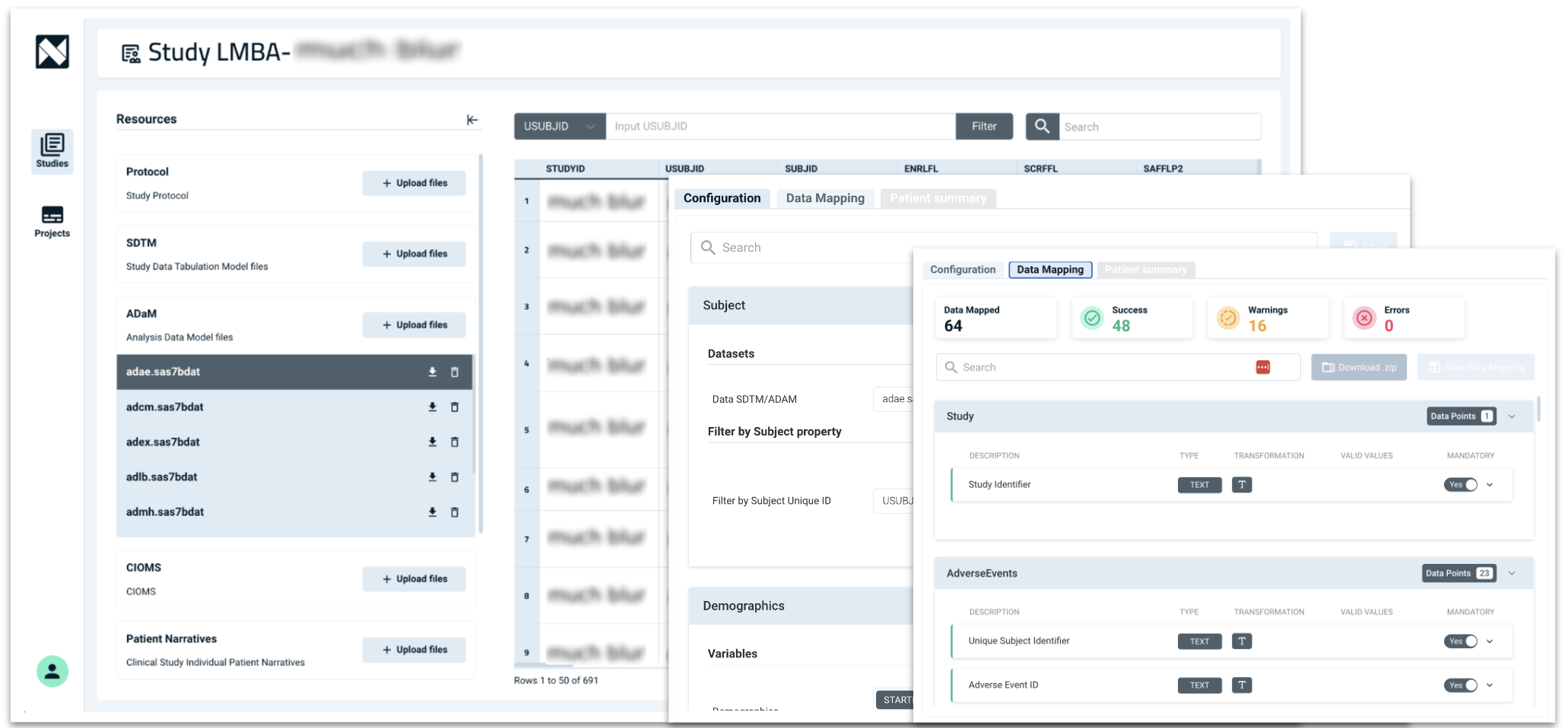
Medical writers use TLFs (Tables, Listings, and Figures) to generate the CSR (Clinical Study Report) body, and Narrativa’s platform makes this process easier. How? By using precisely these TLFs to generate the CSR prose text body. Instead of manually analyzing a demographic table, our AI-powered technology extracts the data, imports it into Narrativa’s Knowledge Graph, and generates clear, concise prose text narrative—saving time and improving accuracy.
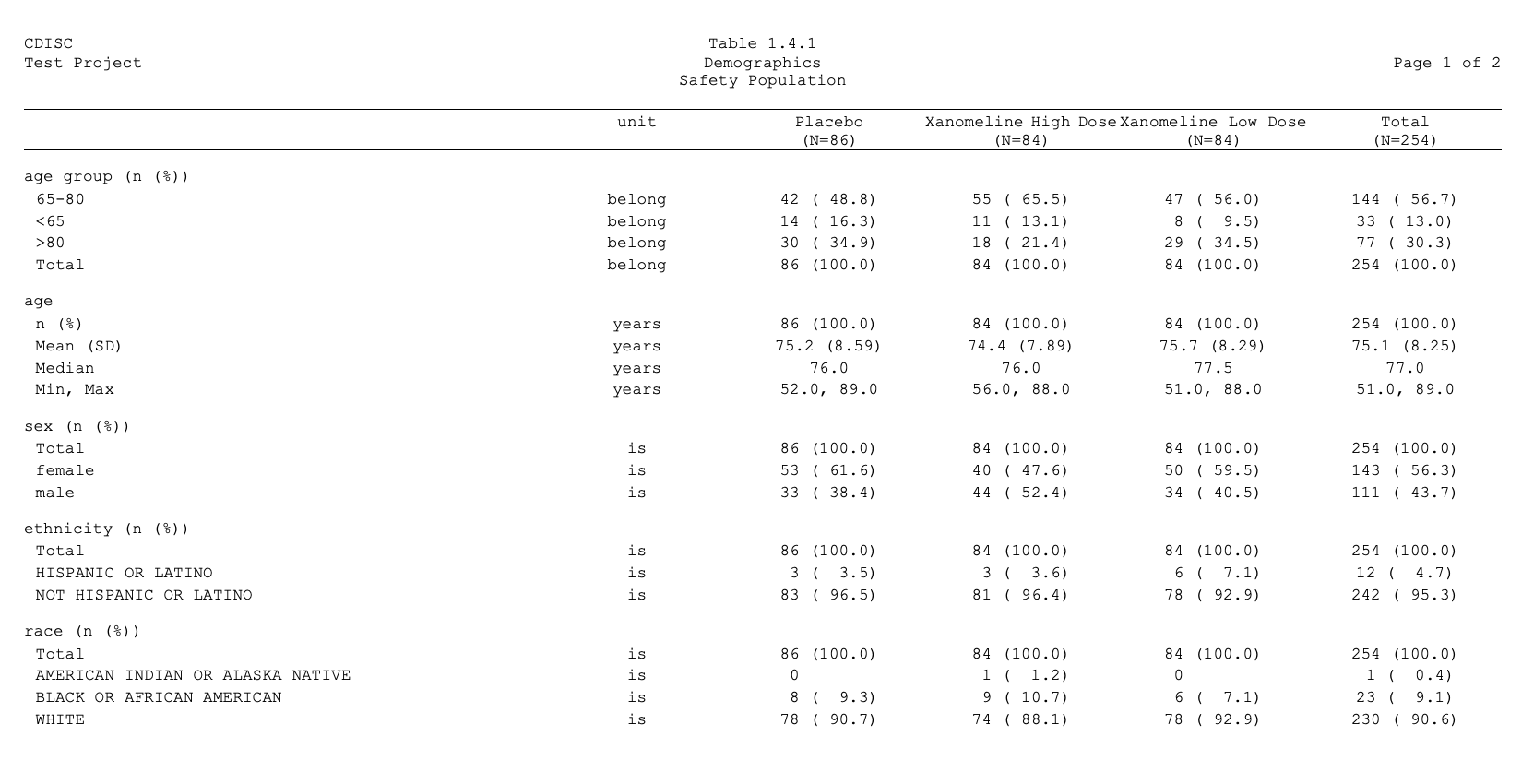
The platform enables reading TLFs (Tables, Listings, and Figures) in PDF, Word, and other common formats. These tables often contain large amounts of complex information, which can be challenging to analyze at first glance.
Narrativa’s agentic AI platform can even process tables that span multiple pages. How? We use artificial intelligence models to extract the information from the table and then transfer it to our proprietary Knowledge Graph.
At Narrativa, we combine data-to-text technologies with large language models to generate text based on table data. This generation can be done using system prompts—predefined by our platform—or user prompts, where you specify the information you need.
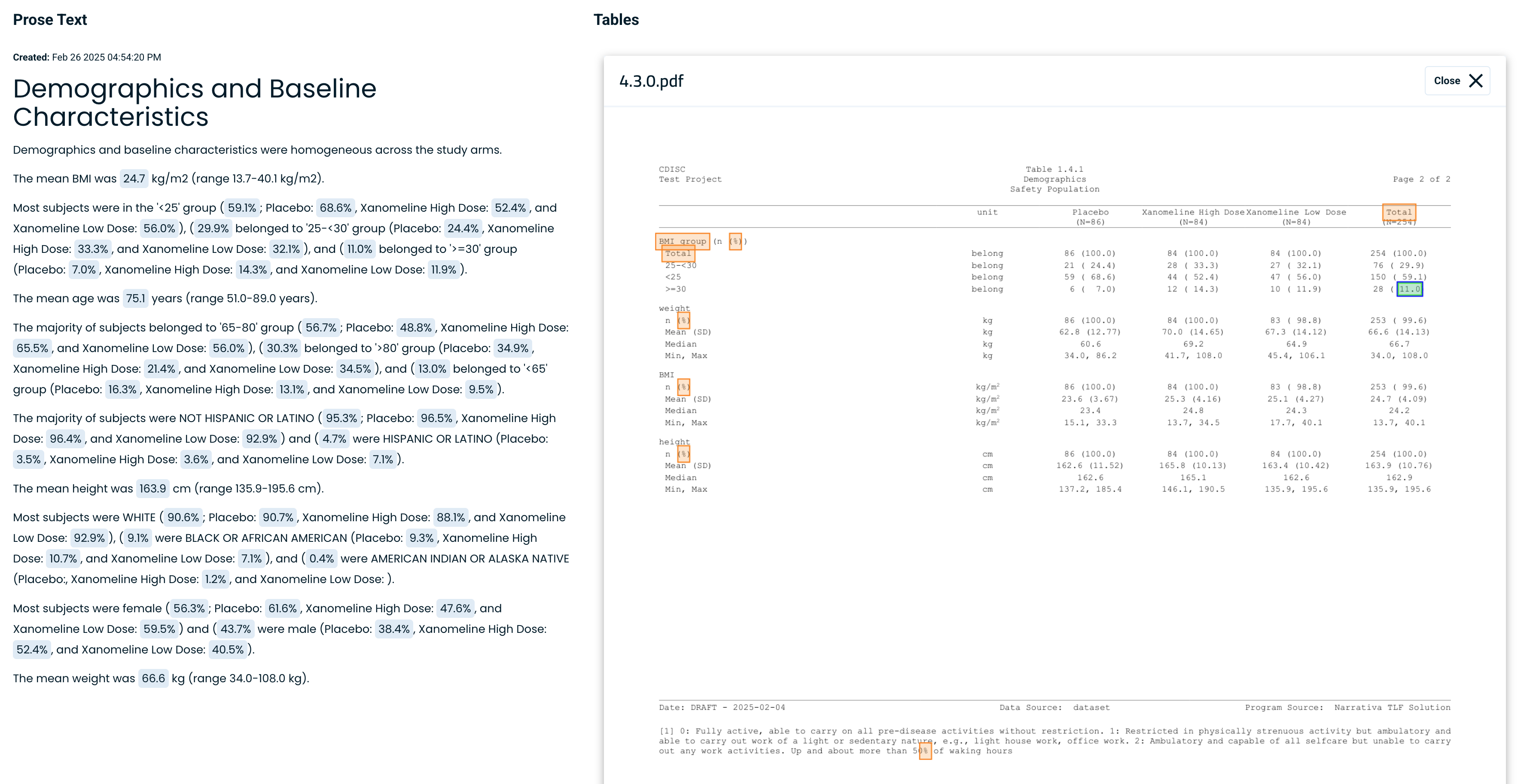
Since this is an initial draft, the medical writer working on the project must validate the text and ensure everything is correct. How? By clicking on any data point (as shown in the image below), the system will locate the corresponding data point in the appropriate table.
This streamlines the medical writer’s QA workflow in just a few simple steps, always under their supervision.
A game-changer for Pharma
Pharmaceutical companies generate massive amounts of structured data in clinical trials, regulatory submissions, and medical reports. Our AI platform streamlines the process by:
- Generating Clinical Study Reports (CSRs): Automating the conversion of structured trial data into comprehensive reports
- Improving Patient Safety Narratives: Quickly summarizing key patient data for regulatory compliance
- Enhancing Table, List, and Figure (TLF) Generation: Reducing the manual effort involved in compiling clinical data for regulatory agencies
By leveraging Narrativa’s agentic AI platform, medical writers and regulatory teams can focus on critical analysis rather than time-consuming documentation tasks. This results in faster submissions, improved accuracy, and significant cost savings.
How does it relate to regulatory submissions?
Regulatory submissions documents, like clinical study reports (CSRs) are based on millions of data points and inputs that could easily involve thousands of patients. Utilizing agentic AI to create text from tables could help medical writers create patient safety narratives or Tables, Lists, and Figures (TLFs) within a few minutes and with minimal effort. So, what does this translate into?
Simply, this means that medical writers will have more time to focus their attention on tasks that require critical thinking rather than repetitive tasks. It also means faster regulatory submission times and reduced costs, as reviews, quality checks, and verifications will be minimized or eliminated.
About Narrativa
Narrativa® Agentic AI solutions unlock a faster, smarter future for life sciences organizations, helping them to efficiently produce complex, high-volume documentation for regulatory and commercialization workflows. By automating content creation, Narrativa® delivers greater speed, accuracy, and consistency—while ensuring full compliance in highly regulated environments.
The Narrativa® Navigator platform provides secure and specialized Agentic AI-powered automation features. It includes complementary user-friendly tools such as Clinical Atlas for CSR and Protocol generation, Narrative Pathway, TLF Voyager, and Redaction Scout, which operate cohesively to transform clinical data into submission-ready documents for regulatory and commercialization. From database to delivery, pharmaceutical sponsors, biotech firms, and contract research organizations (CROs) rely on Narrativa® to streamline workflows, decrease costs, and reduce time-to-market across the clinical lifecycle and, more broadly, throughout their entire businesses.
Explore www.narrativa.com and follow on LinkedIn, Facebook, Instagram, and X.
